只需要3秒钟,一个从未听说过你的AI就能完美模仿你的声音。
你害怕仔细思考吗。
这是微软最新的AI成果——语音合成模型VALL E,它可以在短短3秒内随意复制任何人的声音。
脱胎于DALL E,却专攻音频领域,语音合成的效果在网上发布后走红:
有网友表示,如果把VALL E和ChatGPT结合起来,效果简直爆炸:
看来和GPT—4在Zoom聊天的日子不远了。
还有网友调侃,下一个是配音演员。
那么VALL到底是如何模仿从未听过的声音长达三秒钟的呢。
用语言模型分析音频
基于AI闻所未闻语音的语音合成,即零样本学习。
语音合成趋于成熟,但之前的零样本语音合成效果并不好。
主流的语音合成方案基本都是预训练加微调的模式如果用于零样本场景,会导致生成的语音相似度和自然度较差
基于此,VALL诞生了,它提出了一种不同于主流语音模型的思想。
与传统的利用梅尔谱提取特征的模型相比,VALL直接将语音合成视为语言模型的任务,前者是连续的,后者是离散的。
具体来说,传统的语音合成过程往往是音素梅尔谱波形的方式。
但是VALL把这个过程变成了音素离散音频编码波形:
在模型设计方面,VALL E类似于VQVAE,将音频量化为一系列离散的令牌,其中第一个量化器负责捕捉音频内容和说话人身份特征,后面的量化器负责细化信号,使其听起来更自然:
然后,在文本和3秒声音提示的情况下,自回归输出离散音频码:
那么VALL E在实际测试中的效果如何呢。
甚至可以还原环境背景声音。
根据合成的语音效果,VALL E可以还原的不仅仅是说话者的音色。
不仅声调模仿到位,还支持多种不同语速的选择。例如,VALL E在说同一句话两次时给出两种不同的语速,但音色相似度仍然很高:
同时,连说话人的环境背景音也能准确还原。
此外,VALL还能模仿说话者的各种情绪,包括愤怒,困倦,中立,愉快和恶心。
值得一提的是,用于VALL E训练的数据集并不是特别大。
相比OpenAI的Whisper,花了68万小时的音频训练只有7000多个说话者和60000个小时的训练,VALL E在语音合成相似度上超过了预训练的语音合成模型YourTTS
此外,YourTTS在训练期间已经提前听到了108个扬声器中97个的声音,但在实际测试中仍然不如VALL。
一些网友已经在想象它可以应用在哪里了:
不仅可以用来模仿自己的声音,比如帮助残障人士完成与他人的对话,还可以在不想说话的时候用来代替自己发出声音。
当然也可以用来录有声书。
可是,VALL E还没有开放源代码,所以它可能要等待一个审判。
一个是南开大学和微软研究院联合培养的博士生王成意他的研究方向是语音识别,语音翻译和语音预训练模型
陈三元,哈尔滨工业大学和微软研究院共同培养博士生他的研究兴趣包括自我监督学习,自然语言处理和语音处理
合著者吴语,微软亚洲研究院NLP组研究员,北京航空航天大学博士他的研究兴趣是语音处理,聊天机器人系统和机器翻译
纸张地址:
音频试听地址:
参考链接:
郑重声明:此文内容为本网站转载企业宣传资讯,目的在于传播更多信息,与本站立场无关。仅供读者参考,并请自行核实相关内容。
 顾湘里,合作优势有哪些呢
顾湘里,合作优势有哪些呢
证券之星消息:俗话说的好,“一方水土养一方人”,对于在外打拼不能...
 四方井
四方井
所属公司:桂林临桂横山四方井食品有限公司法定代表人:刘*弟电话:...
 珠乡
珠乡
所属公司:广西北部湾珠乡橄榄食品有限公司法定代表人:王*电话:0...
 红螺
红螺
北京红螺食品有限公司是一家具有多年果品生产经验“中华老字号”企业...
 Caltrate钙尔奇
Caltrate钙尔奇
钙尔奇,较早进入中国的国际钙补充剂品牌,被众多中国医学专家和营养...
 统一
统一
统一企业于1967年7月1日成立于中国台湾台南,涉足食品、金融、...

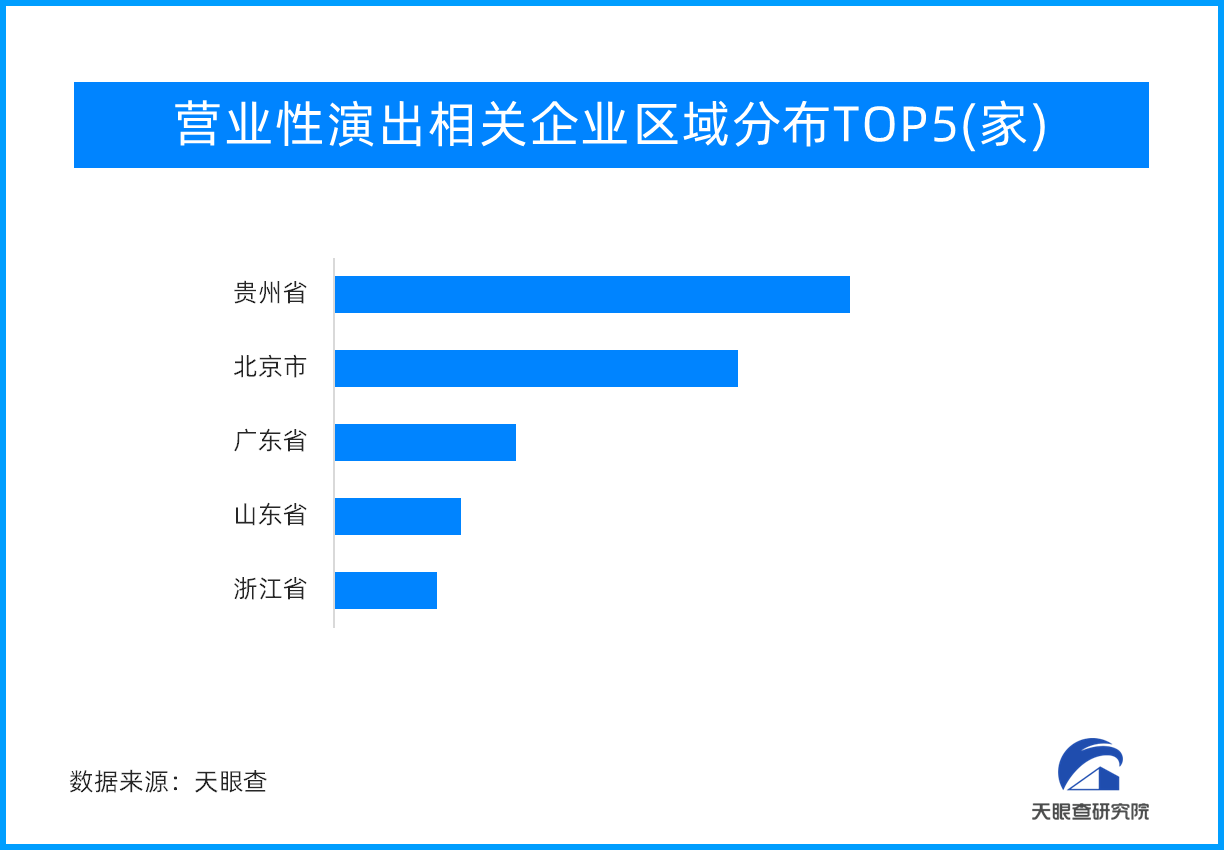 旅游市场带“火”演艺市场 营业性演出超20亿元,
旅游市场带“火”演艺市场 营业性演出超20亿元,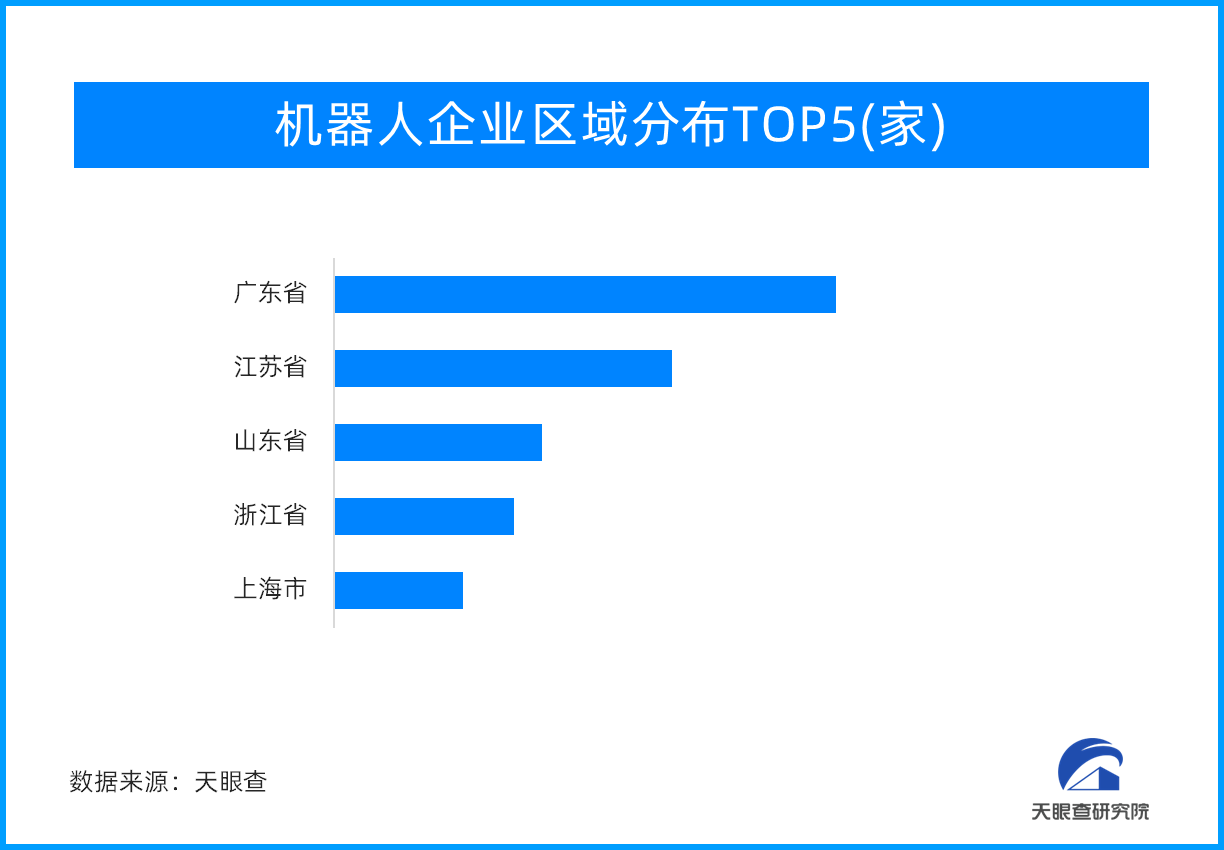 2023世界机器人大会今日开幕!上百家企业携近6
2023世界机器人大会今日开幕!上百家企业携近6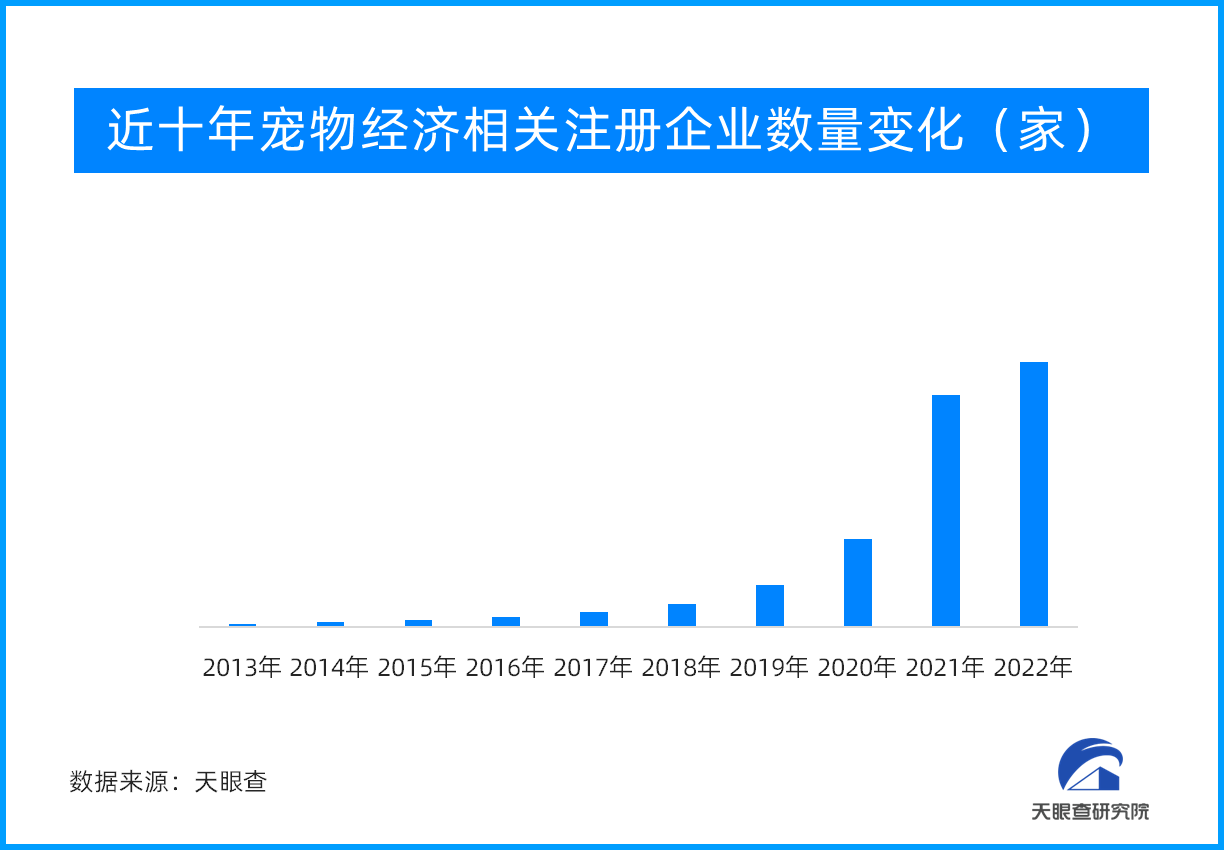 “小”产业 大”钱”途:宠物经济高速发展催生市场
“小”产业 大”钱”途:宠物经济高速发展催生市场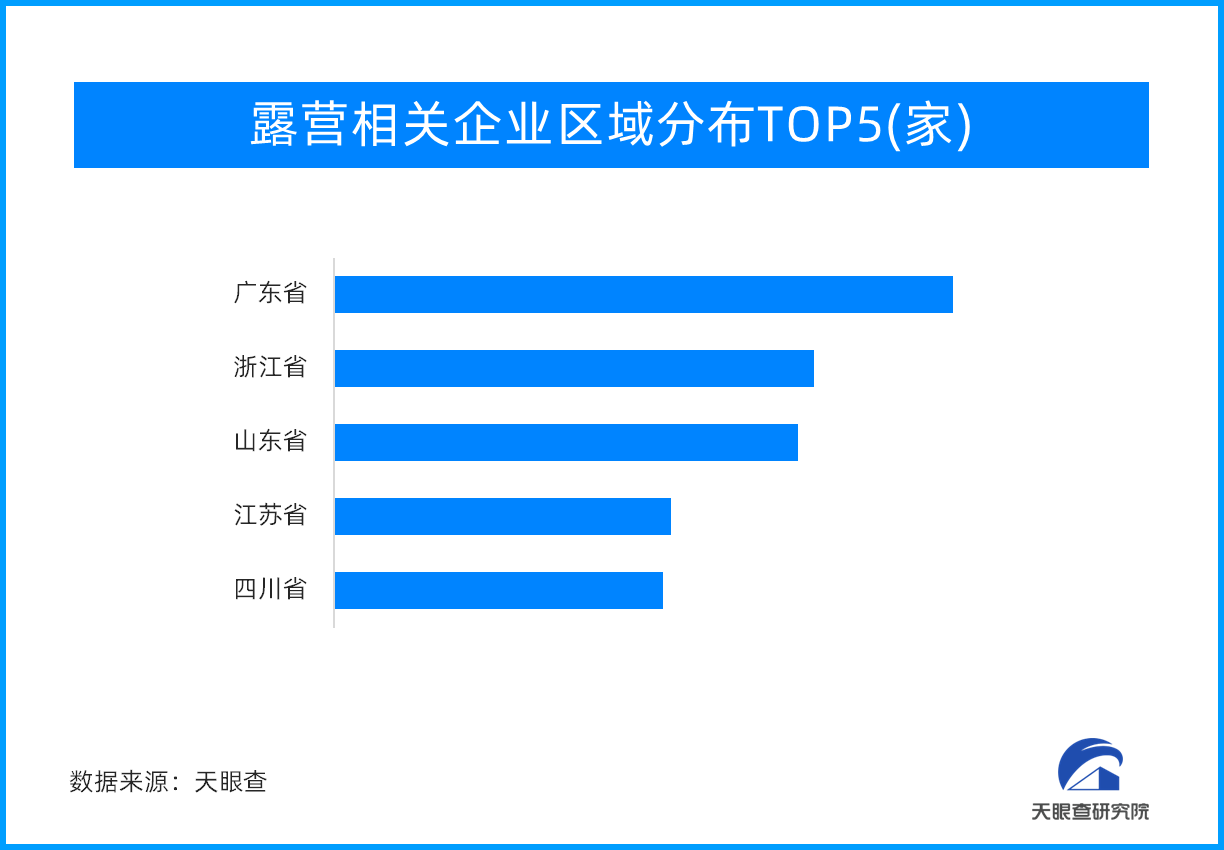 端午到 好出游!远离都市喧嚣 享受亲子时光 露营
端午到 好出游!远离都市喧嚣 享受亲子时光 露营 五年几近翻番,四千品牌登场! 天眼查:哪个赛道“
五年几近翻番,四千品牌登场! 天眼查:哪个赛道“