张鹏
国内的科技创新历史上,从没有哪一次像大模型技术这样,短短几个月就建立了「科技圈共识」。
我 1998 年入行科技圈,见证了 PC 时代、互联网时代、移动互联网时代这几个时代变迁,从来没见过这么迅猛的「共识达成速度」。就拿极客公园的创业者社区 Founder Park 来说,因为比较早关注到大模型领域的技术变化,在短短 4 个月时间就新增了 15 万关注者,社区成员已经扩充到七八千人之多。
就在昨天,首批国产大模型通过备案,又点燃了人们的热情。备案制管理,意味着对大模型发展的政策上的宽松,这也意味着大模型在国内的商用和产业化将真正开启。
只不过「共识」达成的太快也会有让人担心的地方,因为这个技术还在早期发展阶段,也还做不到「水银泻地」般落地到广泛领域。
客观地说,如果相信大模型技术带来了 AGI 的曙光,那么就要坦诚看到其真正产品化,并成为生产力,现在才算开始探索。那些在一线的创业公司经历的 KnowHow 和问题,恰恰是最值得被汇聚起来的星星之火。
基于这个想法,阿里云联合 Founder Park 邀请了 20 多位中国大模型领域模型层、工具层、应用层的优秀创业者,到杭州西溪湿地做了一场面对面的闭门交流。
阿里云董事长张勇还给这场闭门会取了一个很好的名字——「西溪论道」。这场长达五个小时的闭门会,张勇就坐在我旁边,全程参与到创业者的群聊,我看他笔记就写满了好几页纸。
看得出来,阿里云作为算力基础设施层应该如何与这几个层面连接与共创,如何支持各个层面的创业者做好大模型用好大模型,这是张勇最关心的话题。这显示了阿里云跟国内其他公司完全不同的姿态,如何促进大模型生态繁荣才是阿里云最关心的事情。
这些堪称国内大模型领域最积极最活跃的力量,从下午两点一直聊到了晚上九点,从产业的多个层面,立体地做了交流碰撞,也从各自的最新实践中聊出了很多有洞见的观点。按照他们的说法,在这里一起讨论,听到了很多真话,很多「真情实感」。
我整理了一部分印象深刻的要点,用这篇文章也分享给大家。
01关注大模型,更需要关注 infra
现在全球任何一个地方,做大模型,最稀缺的资源除了人才,就是 GPU。
百川智能创始人amp;CEO 王小川分享他去硅谷和朋友聊到,英伟达一年的 GPU 出货量在 100 万颗,但 OpenAI 说要设计 1000 万颗 GPU 连在一块的超算。所以 GPU 到底多少算够,有限的算力有解吗?
创新工场董事长、零一万物创始人李开复表示,尽管千万张 GPU 是天方夜谭,但是「大力出奇迹」的暴力美学是有背景的。强化学习之父 Richard Sutton 在《The Bitter Lesson》中指出:过去七十年,想在 AI 里放一点知识进去,想要增加一点能力,想调一调模型架构,最后发现基本没有价值。唯一推动过去七十年 AI 进步的力量,就是一个通用且可扩张的计算能力。计算能力增强了,相应地带动算法、带动数据的进步,这是大力出奇迹的背景。
因此,在这波大模型浪潮中跑出来的公司首先要有算力,几个人、几十张卡的「禀赋」,还是去选择调用中心化的大模型可能更务实。
「当有了相对足够的算力,在这个前提下好好利用算力,可以做出很多今天只用开源、只调 Llama2做不出来的东西」。前有 OpenAI 不计成本地设立模型新标杆,后有 Meta 开源为所有人铺平道路,在风云诡谲、高度不确定的大模型创业环境中,这是李开复对大模型公司新目标和新实践的思考。
这个打法是什么?怎么让一块 GPU 发挥两块、甚至三块的能力?这个问题可能要在团队构成上更加讲究。李开复认为,Infra团队必须比 Modelling(模型)团队还要强大。他说很快大家就会发现,做过大模型 Infra 的人比做大模型的人还要贵、更稀缺;而会做 Scaling Law(扩展定律,模型能力随着训练计算量增加而提升)的人比会做大模型 Infra 的人更稀缺。
因为优秀的 Scaling 团队可以规避徒劳无功的训练,当做训练的时候,大概率会成功,一旦不成功,也有能力马上叫停,有足够的数学能力来做这件事情。除此之外还有很多微妙的细节和经验,比如,读通论文也会少走很多弯路,因为有些论文是故意把不奏效的东西写出来,不会读很容易被带偏。
其实客观来看,GPU 短缺这个问题,不只是中国创业者的问题,全球创业者都要面对。所以怎么把有限的算力做好,会成为大模型公司角逐的关键。
李开复就提到一个明确的观点:大模型团队每一个位置都要有人才,Pre Train、Post Train(训练后)、Multi-Modal(多模态),Scaling Up(可扩展性),Inference(推理)等等都有其重要性。其中,Infra 团队这部分人才更稀缺,更应该被重视。
其实除了创业者自己对大模型要精进更深入的理解,也需要更多维度的技术创新,比如现场一位 infra 层的创业者,墨芯创始人amp;CEO 王维就分享了一个计算上的解决方案——稀疏计算。让我看到了云端和终端 AI 芯片加速方案通过优化计算模式,能将神经网络开发全面稀疏化,提供超高算力、超低功耗的通用 AI 计算平台的可能性。
02ChatGPT 点燃热情,Llama2 让人脚踏实地
如果说 ChatGPT 点燃了很多创业者的热情,那么Meta 开源的 LLaMA和 LIama2,就让绝大部分创业者在基础模型的起跑线上「众生平等」了。但未来朝着什么方向发展,创业者根据自己的资源禀赋、能力结构,显然会有不同的使命和愿景。
对于仍选择做基座大模型的创业者而言,开源的底座只是起点。李开复就指出,尽管在跟 GPT-3、GPT3.5 等 SOTA模型的各种评比中,Llama2 的差距不大。但实际上用起来,今天 Llama2 的能力跟 GPT-4,以及 Bard(谷歌的大语言模型)的下一个版本,差别巨大。
这看起来也给了做大模型的企业一些腾挪空间,在未来,「真有钱」、「真有本事」的大模型创业者,有机会切换到一个 New Bard 或者 New GPT-4 的打法。
另一方面,不少创业者表示,Meta 开源带给业界的触动很大,「今天 xxx 可能还是中国最好的模型,但明天它可能就被超越了。甚至突然有一天会发现你原来练的那些模型基本都没啥用,当技术换代或者更强的开源模型出来,过去的投入可能完全「打水漂」,比如开源模型在预训练上看了一万亿的英文 Token,你自己的模型非要再看一遍,可能毫无意义。」出门问问创始人amp;CEO 李志飞认为,要充分看到开源带来的深远影响。
「大家虽然都有伟大的理想和抱负,但取决于是否有足够多的经费来支撑到那一天。所以要脚踏实地得看到那,活着可能比什么都重要。」澜舟科技 CEO 周明也认为,很多原先想做「最好大模型」的企业,其实需要重新思考创业的生态位,选择拥抱开源,在开源的底座上做「为我所用」的东西。比如英文开源的模型在中文能力上较弱,也没有在行业场景、数据中打磨过,这恰好是创业团队的机会。
在这一点上,澜舟科技把开源模型当 L0 底座,在这之上,做 L1 语言模型、L2 行业模型、L3 场景模型。周明认为,这样一层一层做好,跟客户通过 AI Agents来互动得到反馈,模型一点点迭代,会逐渐建立壁垒。即便未来有更好的开源模型出现,也有办法在它的基础上再重新训练或继续迭代。「开源模型『水涨船高』,你随着比你厉害的人的成长而成长。」
用好开源模型,也是一种壁垒和门槛。这可能和很多人想象的不太一样。甚至有人会问,基于开源模型做,还算做大模型吗?另一边,很多企业自身也避谈使用了开源模型这一话题。
其实,基于开源模型做,后续的投入门槛并不低,能力要求也不低,用开源只是有效降低了冷启动的成本,对创业者这并不丢人。比如李志飞分析认为,一个开源模型可能看过 1 万亿 Token 的数据,帮你省了几百万美金,模型厂商需要接着再往下训模型。最终要把模型做到 State of the art的水平,数据清洗、预训练、微调、强化学习,各个步骤都不能少,每年算力可能千万美元起,并不见得一下子门槛就没了,更不是使用开源模型就不用继续投入了。
从这个角度来看,开源模型是更务实的选择,优化、训练出实用的模型反而也是真本事。基于开源,有机会做出很好的大模型,核心是能够拥有相对领先的认知,有持续迭代模型的能力。
03大模型 ToB 现状和实践
模型能力的提升是一方面,落到客户场景,又是另一回事。
从客户的角度来看,大模型,「大」并不是唯一的追求,甚至完全不一定是客户想要的。
有创业者就分享了特别现实的客户场景:真正去跟 B 端客户谈,客户只需要语言理解、多轮对话和一定的推理能力,其他的 AGI能力一概不要。
客户向他反映说,其他功能反倒带来了麻烦,「幻象」问题解决不了,而且客户原本有很多 AI 1.0 的模型,本来用得好好的,为什么要扔掉不用,AI2.0 并不需要覆盖 1.0 的能力,能合理调用就挺好。这也解释为何在国内外 RPA 领域是引入大模型最积极的。来也科技联合创始人amp;CEO 汪冠春今年在国内市场也验证了客户有这方面的明确需求。
这种情况下,只要把自然语言理解清楚了,把参数传过来调用 AI 1.0 的模型以及外部数据库,结果是可靠的,成本也比较低,最后再用大模型把结果组装起来,形成一个报告。模型在这里起到了任务分发的作用:分成子任务、每个子任务调用什么。在子任务里,有些大模型支撑的,有些是原来的统计模型,有些甚至都不是自己的,而是某个第三方的模型,客户最后要的,只要能完成任务就行。
尝试找到这样的 PMF后,如果只做这种 To B,其模型能力包含语言理解、多轮对话和少量的推理,这个模型并不需要很大,100 亿到 1000 亿的模型,就相对够了。相应地,需要在几百张卡的基础上,把语言理解、多轮对话做好,并且有一定的推理能力,再加上 AI Agents,基本上能完成客户在很多场景下的需求了。
一个通用的大模型,并不意味着可以解决所有问题。B 端客户的很多场景,通用大模型放上去并不奏效。这意味着模型需要越来越多,有越来越可收敛的场景,也意味着需要更多力量参与进来帮助技术和场景的对齐,而不是一个万能的技术去适配所有场景。
澜舟科技 CEO 周明认为,必须要把用户数据、行业数据,甚至图谱或者规则,放到模型里继续训练,这是行业大模型存在的必要性。在通用大模型不能覆盖到的局部行业,加入这样的数据,能把行业问题解决得很好,而且还能克服很多幻象问题。
我记得李志飞也补充了这一视角,他认为,通用大模型与垂直大模型,各尽其用,鱼与熊掌不可兼得。模型特别大,就意味着推理成本非常高。而且,一个做芯片设计的大模型,去回答电影、明星等娱乐内容,也没有意义。他认为,To B 更多是要垂直和可靠,而通用在于智商,有很强的推理能力、逻辑能力,很丰富的知识。这不一定是 To B 目前阶段需要的。
与此同时,国内各行各业对于在业务中加入大模型的需求,是非常强烈的。蓝湖创始人amp;CEO 任洋辉,和 Moka 联合创始人amp;CEO 李国兴,这两家 SaaS 公司产品接入大模型后,已经得到了客户的认可,真正收到了钱。
通过对这两位创业者从 2、3 月份到 7、8 月份的状态变化的观察,我发现SaaS 领域中越早看到大模型带来的技术变化是「重新定义软件」级别的,敢于拿出「向死而生」的思维来实践这个「重新定义」的进程,基本上几个月就会破除焦虑,并且让人看到希望。
所以,手里拿着客户和场景的创业者,搞不好会是那些大模型创业者的更早获得技术红利的受益者。
因为落到具体场景下,大模型其实就会有不一样的追求。比如华深智药创始人amp;CEO 彭健表示,大模型带来的幻象对药物设计这样的 AI for Science 领域可能是有益的,某种程度上,所谓幻觉在某些领域就是智能的意义所在,因为这可以帮助设计出人想不到的蛋白质组合方案。
就像智谱 AI 作为国内大模型落地案例跑得最多最快的一家,其 CSO 张阔在实践中就认为,对未来大模型的价值来说,「20% 可能是中心化的,80% 会是非中心化的」,也就是说用更丰富的、更多种类的大模型具体到客户场景里去产生价值,而不只是一个大模型无限泛化能力去解决所有问题,这是一种必然的趋势。而这也得到了一起交流的很多创业者的认同。
04AGI 值得献身,但也不要「玩命」
大模型是 AI 的一个分水岭。过去,人工智能是在封闭的系统追求确定的目标,比如人脸识别系统追求百分之百准确,但现在,大模型带来的「涌现」是一种开放的智能,产生各种各样的可能性,超出设计者预料之外,这是智能真正的特点,也是人工智能六七十年来最大的一个变化。
出现这样一种新的智能系统之后,未来大家都能很便利地、低成本地地获得智力,就像电力革命一样。
智源人工智能研究院院长黄铁军认为,这次技术变革向下传递得很快,从大厂到创业公司迅速共识:这是一个新时代的开始。在这个时代不干点啥,好像对不起这个时代,对不起技术的发展。
而 4 月份下场的百川智能算是目前国内做大模型最「卷」的一家,保持平均 28 天发一个模型的节奏,百川智能创始人amp;CEO 王小川虽然不承认自己在「卷」,但他分享了快速落地的法门:比如搜索技术有积累的团队,对数据处理问题上是有很大帮助的。而且通过引入搜索增强、强化学习,以及其他配套性的全栈技术,确实可以来帮助模型做得更好。「如果看一下现在场内技术公司的高层背景,你会发现很多技术做的不错的都有搜索背景,这里面体现了一些技术的逻辑正在逐渐被看清楚。」
不过黄铁军认为,从科研角度来说,我们依旧只是进入一个伟大时代的早期,如果类比电力时代,今天这样一个智力时代,其实就是当年法拉第搞发电机,一旋转,电流产生了;现在是用大数据训模型把智力训练出来了,这是一个阶段。后边我们还需要一个人——麦克斯韦,因为后边电磁学的确立,才是电力在人类社会开始靠谱可用、并推动工业革命的前提。
今天的大模型还有很多东西是黑匣子,一方面大模型的「上限」还有巨大提升空间,AIGC 很多时候能带来巨大惊喜,但另一方面大模型的「下限」却还不能保持足够稳定,这个时候理解技术的边界,合理的设定目标和要解决的问题,是很有必要的。有人要解决上限的探索,有人要解决下限的稳定。
对创业者们来说,AGI曙光已经出现,这是一件值得投身的事业,但也不要「玩命」。
另一边,除了等待大模型技术更进一步,很多中间层的创业者在改进让大模型落地到应用的环境。
BentoML 亚太区负责人刘聪称,和之前传统机器学习相比,海外客户基本都能拿到一些预算来做大模型相关的产品原型或者 Demo。但现在还没有进入生产环境,去为公司产生商业价值,而很多做中间层的创业者看到了这个机会。
Dify.ai 创始人amp;CEO 张路宇的创业洞察也正源于此,他说,在开发者视角,拿到模型是不够的。他分享了一个数据,在对六万多个应用的样本做分析后,发现现在投产或者接近投产的,这个比例差不多是 5%。有对模型技术不是很满意的,也有团队工作流还没有适应 AI 应用开发的。相应地,张路宇团队针对现在投产可能性更高的应用,去做一些专项能力。比如他们有一个指标叫消费者摩擦度的改进,看 AI 在这件事上能提供多大的价值,提供相应的能力。
Zilliz 创始人amp;CEO 星爵补充了这一视角,他认为一个极度简单的开发栈,是AI民主化的一个前提,基于这个判断,他提出了 CVP这样的开发栈。
05如何通向 AI native?
什么是 AI 时代的的 Killer App,在今年 3 月微软发布 Copilot 之际,很多人的好奇被瞬间点燃。但在这次闭门会上,李开复提出了一个不同的视角,Copilot 不算是 all in 大模型的产品。
从这个视角看,AI native的应用可能有这样的特征:如果大模型拿掉了,应用就崩溃了,它是一个完全依靠大模型能力的应用。但拿掉 Copilot,Office 软件还是 Office,AI 只是锦上添花。
这一观点得到了现场创业者最多的认同,也引发了大家带着这个定义,对 AI native 应用的探讨。
前段时间爆火的产品妙鸭,其产品负责人张月光认为,没有大模型,就没有妙鸭,这跟李开复对 AI first,AI native 的思考一致。
他认为,妙鸭作为率先出圈的应用,最重要的是解决了可控性。妙鸭团队一开始没有想做底层模型的工作,更关注怎么才能用现存生态上开源爱好者开发的各种插件和小模型做可控性。锚定了最重要的事情是可控性,妙鸭把照片质量做到平均分 90 分以上,也迎来了快速成功。
「我们在应用层特别关注怎么才能让模型更可控,就发现在图像赛道上,已经有一些相对可控的技术了。可能语言赛道上,如果出现这样的东西,会对上层应用创业者是一个质变时刻」。张月光的实践给了做大模型应用的公司一些启发,可控性可能是 AI native 应用诞生的条件。Stability. AI China Lead 郑屹州也观察到了这样的趋势,开源社区贡献者解决可控性后,大量应用冒出来了。
在探索新一代应用上,元石科技创始人李岩指出,大模型带来的推理能力,是新一代产品的本质不同。
而社交+Agent 是被看好的一个机会,并且一定会是最早一批 AI native 的产品,但这很可能需要创业者具备从大模型到产品的「端到端」的构建能力。比如,李志飞分享了和 Character.ai 探讨为什么后者要做自己的大模型时,对方表示,因为用OpenAI或者谷歌这样的中心化大模型,不会回答「调情」的问题。这是 Character.ai 找到的独特空间,也是可以逐渐积累的壁垒。
同一领域的聆心智能,在做社交大模型的应用上,发现了独特场景。聆心智能 CEO 张逸嘉分享了他们看到的与预想的不同,现在大模型可以落地的社交场景不是陪伴,人们接受虚拟形象的陪伴需要时间。现在落地的社交场景是角色扮演,用户画像是网文小说爱好者,角色扮演是网文小说的新形式。
至于现在最新的 AI Agent 方向,是不是大模型「全村的希望」,甚至最终带来交互革命、终端革命、商业模式革命,很可能要取决于多模态能力的发展。
心识宇宙创始人amp;CEO 陶芳波解释说,一开始大家对 Agent 的期待很高,但在现有技术条件下发现,Agent 怎么样比 ChatGPT 解决了更多问题,很难被讲清楚。他认为,如果真的要把 Agent 发挥作用,并不是把那么多软件的 API 给接进来,因为接软件的 API 本质上是在做兼容,是新瓶装旧酒。
Agent 有没有一些更加 Native 的形态去完成最后一公里。有很多很多要做的事情,数字栩生创始人amp;CEO 宋震说的空间感知能力和多模态能力。在这些条件成熟之后,可能就会出现 Killer Case。
李志飞坚定地认为,现在看来,多模态是 C 位,不是花瓶。因为Agent 输入输出都依赖于多模态的能力,没有多模态就没有 Agent,只不过今天的 Agent 更多是通过语言模型,通过文本来反馈,但是最终 Agent 会是一个多模态的观察、感知、行动。他预判,跨模态知识的迁移,再过两、三年看,反而是大语言模型最大的一个贡献。
06大模型时代,服务大 B 还是小 B
几个月前,我在旧金山正好赶上数据公司 Databricks 的开发者大会。这是一家专门做「数据湖」的数据平台公司,可以说是长在云计算平台上的「中间层」公司。就是这样一个公司,几年时间估值已经达到几百亿美元,并且还在持续增长。Databricks 的客户既有大企业,也有小创业公司,大小通吃。
今年,这家公司迅速接入大模型,还收购了大模型公司 Mosaic ML,开始帮助客户落地大模型进入业务,这个风口让它眼看一路狂奔千亿美元价值而去了。
我当时非常好奇的一点是,为什么国内好像没能长出这样一个基于云计算的「中间层」公司,而这一波 AI 技术进步的变量,是否在中国能催生出这样一批在把云的算力变成业务竞争力,带给更多行业数字化进步的「中间层」的优秀企业?
阿里云董事长张勇认为,「中间层」公司的出现,一定是有可能的,也是云计算企业乐见其成的。但这些公司要解决的还是一个核心问题——定义清楚要解决谁的什么问题,定义越清晰,能力越到位,做的东西就能真正「收敛」,真正有商业「穿透力」。
这也引发了参会创业者们的探讨,比如大模型技术刚刚开始进入行业,但企业服务「不收敛」、项目化的问题就开始出现了。比如给 B 端用户做大模型训练,但由于数据是对方的,所以最终合作完,自己的团队很难「闭环」——数据没有飞轮,收入毛利也低,一不小心就做成了「高科技施工队」,是技术企业面对 B 端的一个通病。甚至有创业者都开始怀疑,大模型 To B 可能天生缺乏土壤。
但加入创业者群聊一直在做笔记的张勇,恰恰在这里很体系化地说了一个不同的见解:「To B 其实还有另一种可能,就是「小 B」,也就是那些中小微企业,它们看起来不起眼,但是数量众多,单单服务它们,就能够造就现在的互联网巨头。」
例如,阿里早期的「黄页」,让中小卖家能被外国买家看见,带来了跨境贸易的繁荣;淘宝则是解决了信息和物流的流通问题,就成就了电商这一大品类。
而且,相对于大型公司,这些小 B 公司并不关心技术和愿景,谁能帮它们解决增长问题,就会因此付钱。
当前大公司的数据化,最主要的一个目的就是要「降本增效」,说白了就是「节流」。但效率优化空间总有尽头,可是增长和发展的「开源」空间,却相对无限。张勇认为,企业服务里「开源」远比「节流」重要,人们永远愿意为了发展而付费。
他甚至认为,过去数字化企业服务过于看重「降本增效」可能是个误区,因为愿意为提升百分之几的效率付钱的往往是大公司,他们体量大,这种提升符合投入产出比。然后也让大家都围着大公司做项目。但反过来,小公司很难靠「降本增效」去启动需求,它们要的是成长和发展的能力。
其实,小 B 客户还有一种双重性,即如果采用「订阅」的方式,那它其实就可以被看成是一个「C 端用户」。
在这一点上张勇的观点也得到了参会创业者的认同,比如出门问问的李志飞曾经在语音识别领域做过 To B 的业务,被同行卷得非常痛苦。而后来他做的 AI 配音工具「魔音工坊」,服务的就是一个个内容创作者,收敛到一个真正解决小 B 们普遍问题的产品,这些「小 B」反而让他真正把 AI 技术变成了健康成长的业务。
张勇还建议创业公司需要一开始就确定自己要服务的客户,是 C 还是 B,是小 B 还是大 B,必须定义好。张勇甚至觉得,做 AI 的公司,如果既做 To 大 B 又做 To 小 B 甚至 To C 是行不通的。
虽然 AI 技术的发展带来了很多变化,会越来越有通用的能力,但是在技术层面之外,还有组织的「DNA 问题」,「你一个公司里做大客户的和做互联网用户的团队,上班的着装、说话的方式可能都是不一样的。」张勇觉得要定义清楚自己服务谁,解决什么问题,而不是哪有单子往哪里走。
07大模型对云 意味着什么?
几年前上一波 AI 浪潮中,很多创业公司一样获得了大量融资,出现了很多知名公司和创业者,但是几年下来,依旧做得很辛苦。我和很多那一波创业者一直保持交流,好多次约出来聊天,看到他们一脸疲惫沙哑着嗓子,一问往往是前一天陪某个大客户喝了大酒还没缓过来。
这次的很多创业者也目睹了那个时代,技术最终因为无法形成标准化产品,变成只能接项目的「高级人力外包」、「高科技施工队」。他们都觉得,一定不能再重蹈覆辙。
与此同时,大家也很关心阿里云这样的云计算平台在大模型时代会面对什么变化。大家也问张勇,在大模型时代,他觉得云本身到底是技术,还是产品?
张勇的回应倒是很直接,「云本身应该是产品,并且不是一个,而是一系列的产品。」在大模型和 AI 浪潮推动下,有一个事情是确定的,就是行业和客户对算力提出了全新的要求。如何满足客户对算力的进一步需求,就成了阿里云的基本出发点。张勇觉得这里面一定有技术要解决的问题,但阿里云也一样要思考如何「收敛」到真正解决产业生态问题的产品,而不只是输出算力本身。
有意思的是,这次交流活动虽然是 FounderPark 社区和阿里云联合邀请,但却没有安排任何关于「通义千问」的分享。创业者们当然也很关心云平台自己做大模型的目的。张勇的观点是:这个容易出现 Hyper Scaler的跨技术时代,肯定没有人敢掉队,不可能不去触摸技术本身。但他觉得,阿里云在这样一个巨变时代,要把握的还是更核心的角色,就是Cloud Service Provider(云计算服务提供者)。
「而要做好这个角色,不懂大模型一定是不行的。」张勇说:「我们如果不做通义千问,可能都搞不清楚该如何帮助今天参会的各位创业者们。」
其实让张勇比较兴奋的,是他非常确定未来人类社会对于对算力的需求是无限的,对于其效率的要求也会越来越高。所以张勇说,阿里云肯定是希望「模型越多越好,场景越多越好」,二者越多,对算力的需求和技术要求就更高,这就意味着云有了新的要去面对和解决的问题。而唯有持续不断值得解决的「难问题」,才能驱动云的价值有更大的成长空间。
「云计算平台前所未有需要一个生态,而不是什么都自己搞。目前,还没有一家公司能把芯片、云计算、数据平台、机器学习框架和大模型,全部用自己家的,形成所谓的「闭环」,这几乎在物理上是不可能的。」
张勇觉得,AI 技术的发展,让生态有了新的可能。他有个遗憾,过去十年是中国云计算突飞猛进的时期,但中国的 SaaS 行业,并没有因为基建的快速发展而有了本质性的提升。而美国的 SaaS 公司,目前都在探索将 AI 嵌入到平台中升级,走了一条和国内公司不同的路径。
他认为,在 AI 时代,中国可能会出现新一代的 SaaS,会是一种全新的智能服务,和以前 SaaS 流程驱动不同,这种新的服务会通过数据和智能驱动,可能也不叫 SaaS。
面壁智能董事amp;CEO 李大海指出,国内 To B 市场非常碎片化,这是 SaaS 服务起不来的原因。但是现在有了大模型这样一个技术变量,能不能够形成一些变化,这是比较值得期待的事情。同时他也期待阿里云这样的云厂商,能在这里有一些好的方案和底座,带着大家一起把这个事儿趟得更平。
在张勇看来,中国过去不少 SaaS 公司,到现在也不能安全算是 Cloud Native,而对于一个天然生长在云上,或者是 intelligent native(智能原生)的新型服务,有机会「平替」之前非原生的上个时代产品。
很多时候我们感叹,上一个十年中国的 SaaS 行业成长不尽人意,但大模型如今给创业公司提供了新的机会,在一个全新的数字化生态里塑造新的格局的可能性。张勇的结论是:这样的机会和挑战,对阿里云,对所有创业者,都是相通的,都要面向未来找到自己的位置,共同形成生态伙伴关系,共同创造价值。
好了,以上是我在长达 7 小时交流中节选的一些笔记。我最强烈的感觉是,今天大模型技术带来的时代变化,才刚刚拉开帷幕。经过前半年的极度兴奋和「过度想象」,一个可能长达 10 年的技术革命,现在才真正开启「万里长征」。狂热期之后真正进入拓荒期,这里面经过足够时间磨练和付出坚实代价才能获得的「共识」,才是真共识。
希望创业者之间,产业生态之间,能有更多的带着「开源精神」的坦诚交流和思考碰撞。其实张勇给这次交流起的「西溪论道」这个名字就挺好的。坐而论道,更要起而行之。
我想,这个「道」应该就是 AGI 时代从技术到产品,从 vision 到价值的那个「创新之道」吧。
郑重声明:此文内容为本网站转载企业宣传资讯,目的在于传播更多信息,与本站立场无关。仅供读者参考,并请自行核实相关内容。
 顾湘里,合作优势有哪些呢
顾湘里,合作优势有哪些呢
证券之星消息:俗话说的好,“一方水土养一方人”,对于在外打拼不能...
 四方井
四方井
所属公司:桂林临桂横山四方井食品有限公司法定代表人:刘*弟电话:...
 珠乡
珠乡
所属公司:广西北部湾珠乡橄榄食品有限公司法定代表人:王*电话:0...
 红螺
红螺
北京红螺食品有限公司是一家具有多年果品生产经验“中华老字号”企业...
 Caltrate钙尔奇
Caltrate钙尔奇
钙尔奇,较早进入中国的国际钙补充剂品牌,被众多中国医学专家和营养...
 统一
统一
统一企业于1967年7月1日成立于中国台湾台南,涉足食品、金融、...

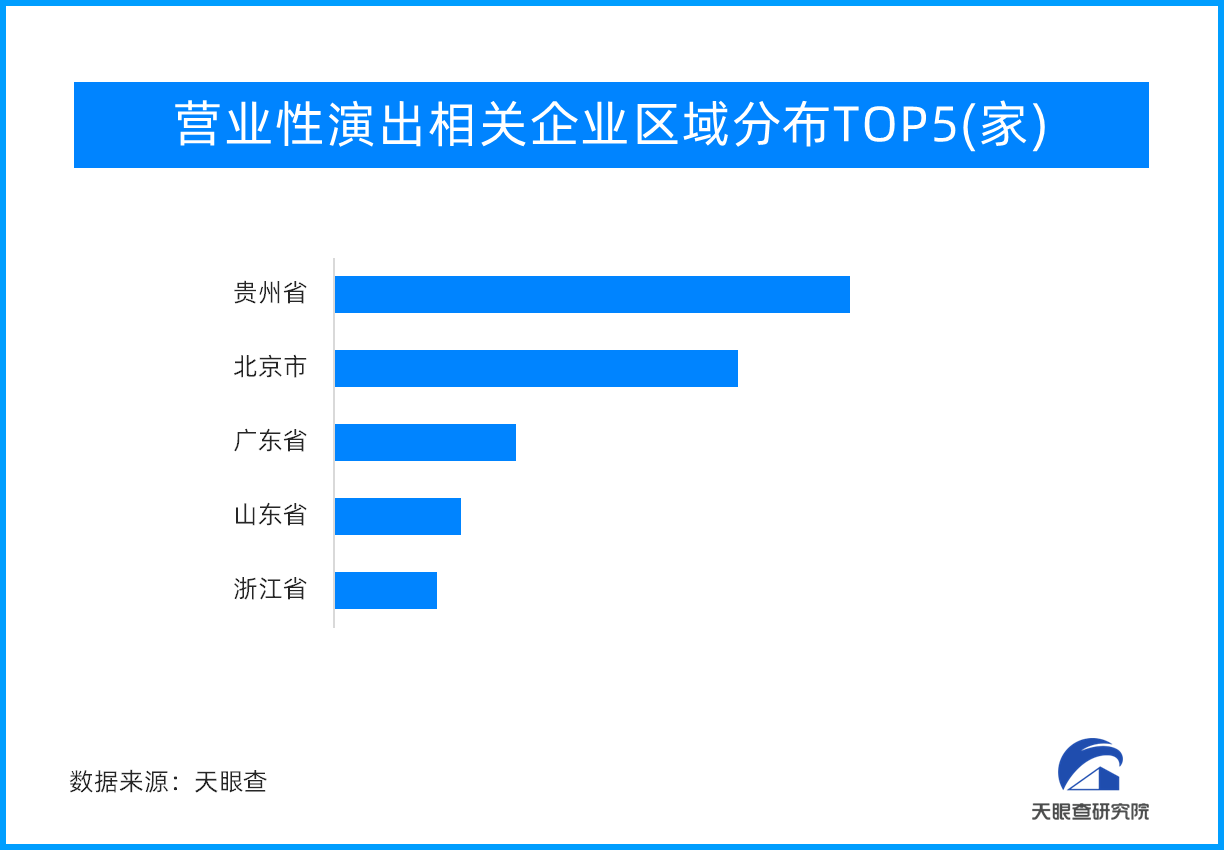 旅游市场带“火”演艺市场 营业性演出超20亿元,
旅游市场带“火”演艺市场 营业性演出超20亿元,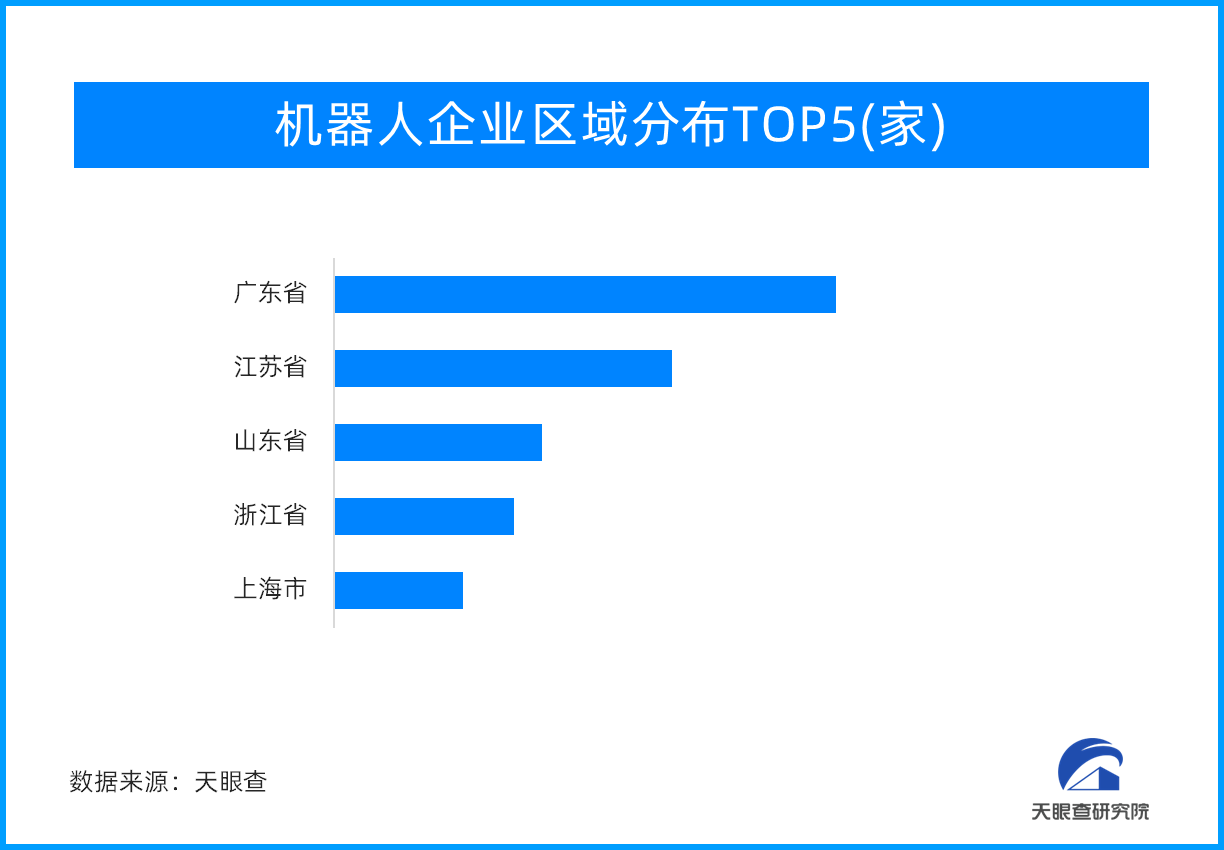 2023世界机器人大会今日开幕!上百家企业携近6
2023世界机器人大会今日开幕!上百家企业携近6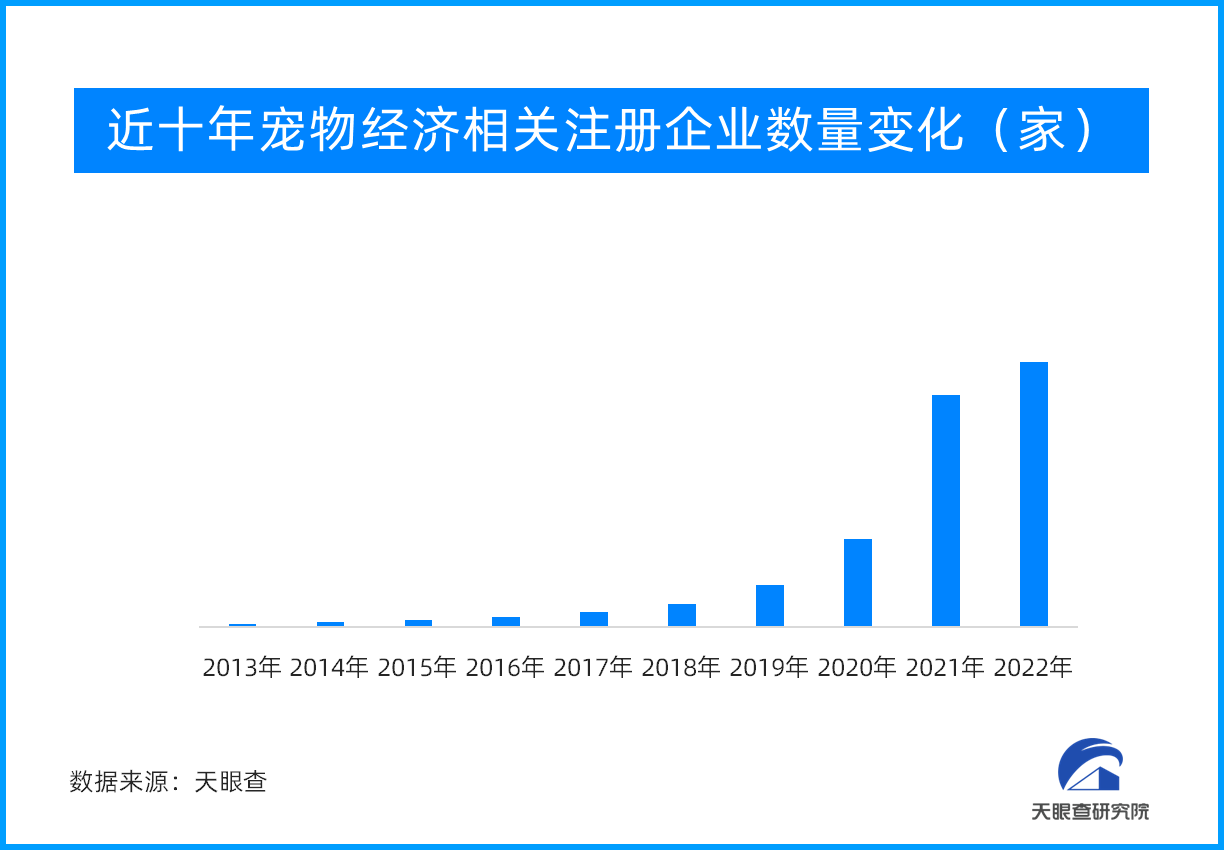 “小”产业 大”钱”途:宠物经济高速发展催生市场
“小”产业 大”钱”途:宠物经济高速发展催生市场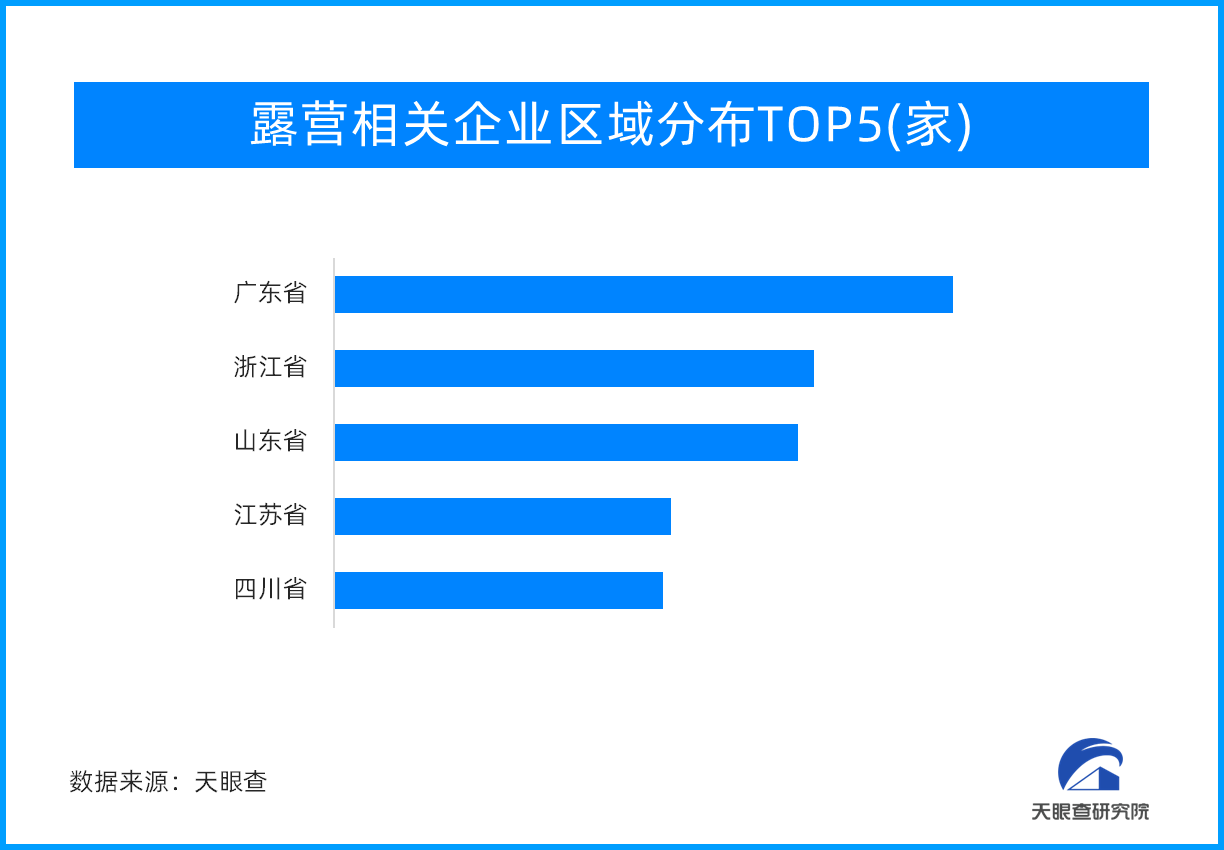 端午到 好出游!远离都市喧嚣 享受亲子时光 露营
端午到 好出游!远离都市喧嚣 享受亲子时光 露营 五年几近翻番,四千品牌登场! 天眼查:哪个赛道“
五年几近翻番,四千品牌登场! 天眼查:哪个赛道“